











Abstract
Text-to-image (T2I) diffusion models have revolutionized visual content creation, but extending these capabilities to text-to-video (T2V) generation remains a challenge, particularly in preserving temporal consistency. Existing methods that aim to improve consistency often cause trade-offs such as reduced imaging quality and impractical computational time. To address these issues we introduce VideoGuide, a novel framework that enhances the temporal consistency of pretrained T2V models without the need for additional training or fine-tuning. Instead, VideoGuide leverages any pretrained video diffusion model (VDM) or itself as a guide during the early stages of inference, improving temporal quality by interpolating the guiding model’s denoised samples into the sampling model's denoising process. The proposed method brings about significant improvement in temporal consistency and image fidelity, providing a cost-effective and practical solution that synergizes the strengths of various video diffusion models. Furthermore, we demonstrate prior distillation, revealing that base models can achieve enhanced text coherence by utilizing the superior data prior of the guiding model through the proposed method.
Method
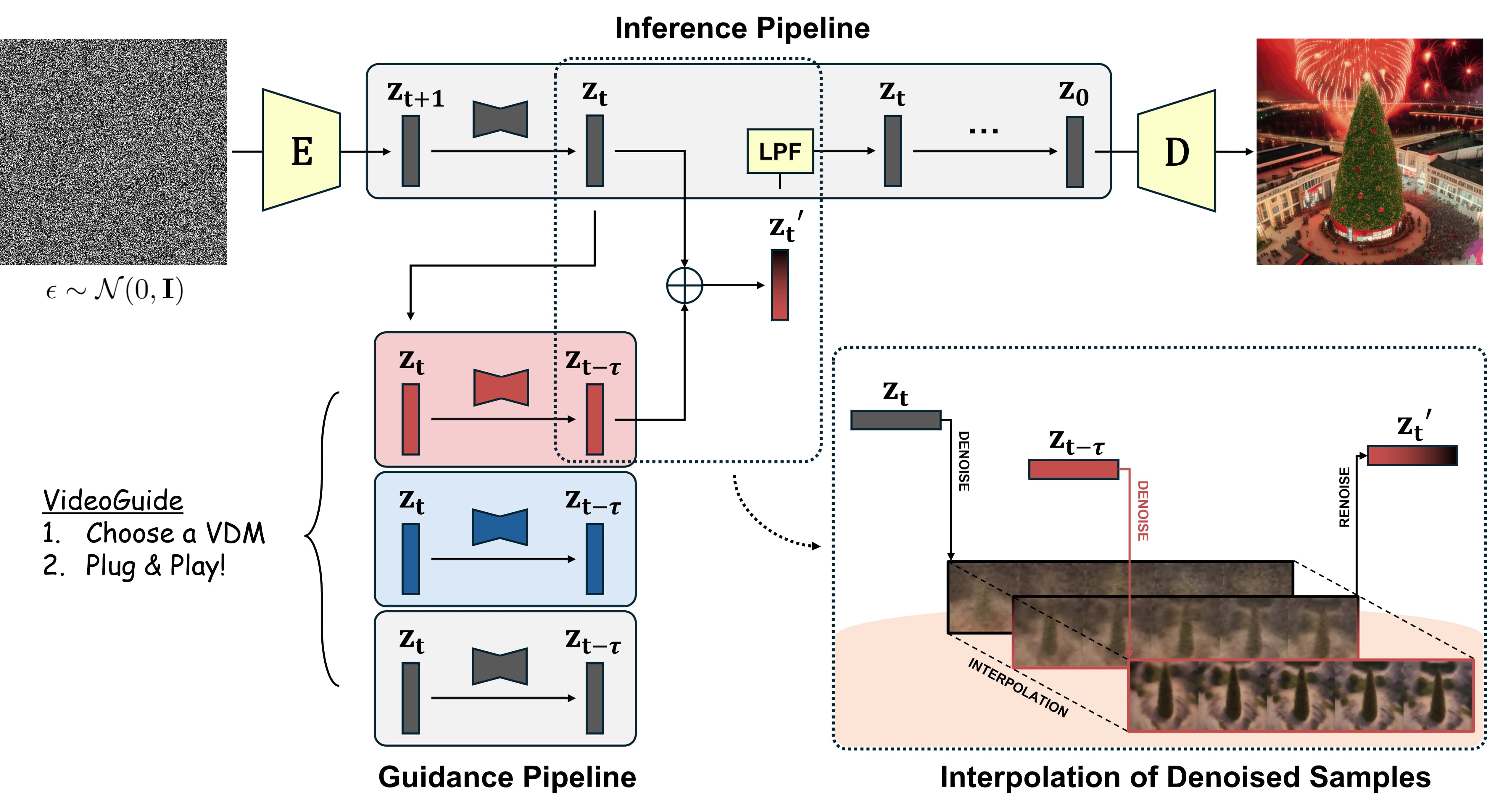
VideoGuide enhances temporal quality in video diffusion models without additional training or fine-tuning by leveraging a pretrained model as a guide. During inference, it uses a teacher model to provide a temporally consistent sample, which is interpolated with the student model's output to improve consistency. This process is applied only in the early steps of inference and includes a low-pass filter to refine high-frequency details. VideoGuide effectively improves temporal consistency while preserving imaging quality and motion smoothness.
Experimental Results
1. Comparison with Previous work


















2. AnimateDiff(RCNZcartoon) + VideoGuide












3. AnimateDiff(ToonYou) + VideoGuide





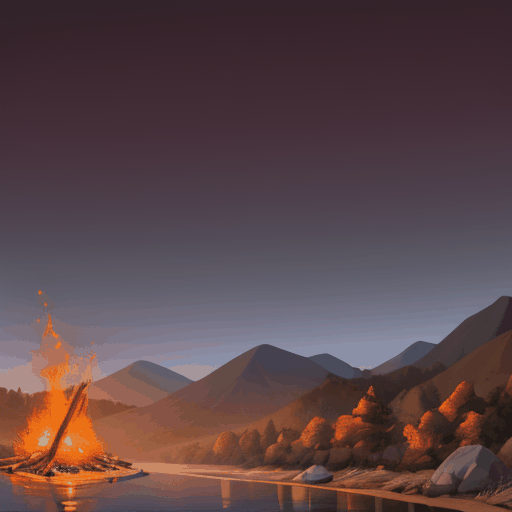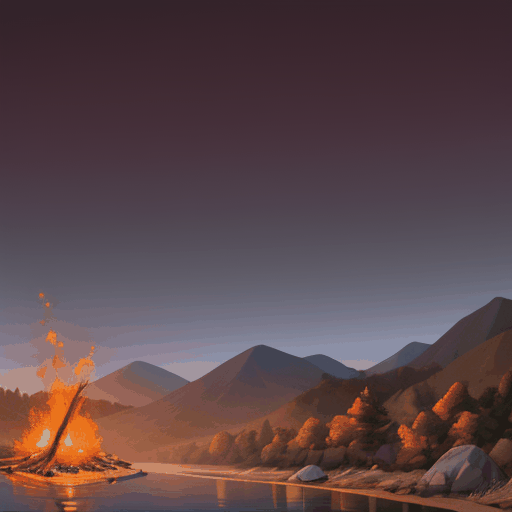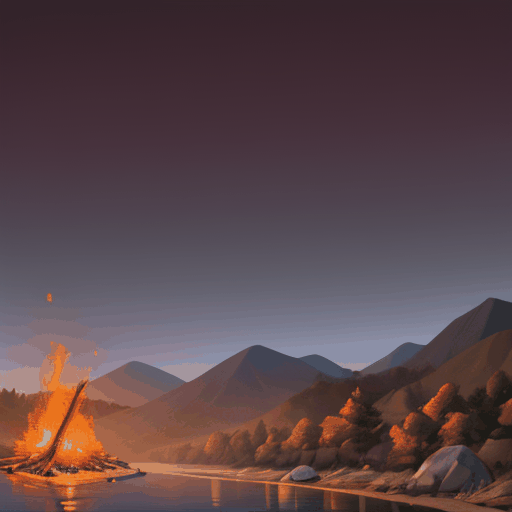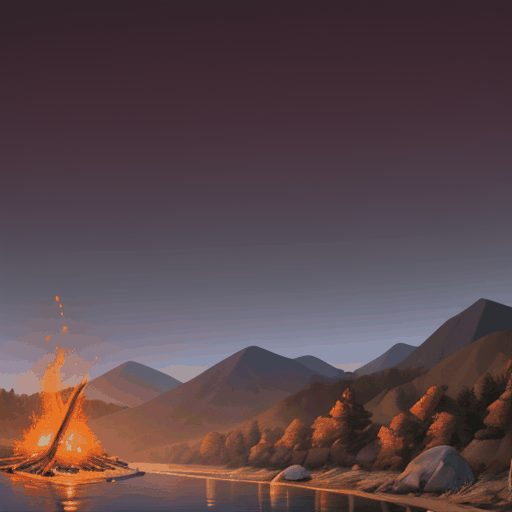






4. AnimateDiff(FilmVelvia) + VideoGuide












5. AnimateDiff(RealisticVision) + VideoGuide











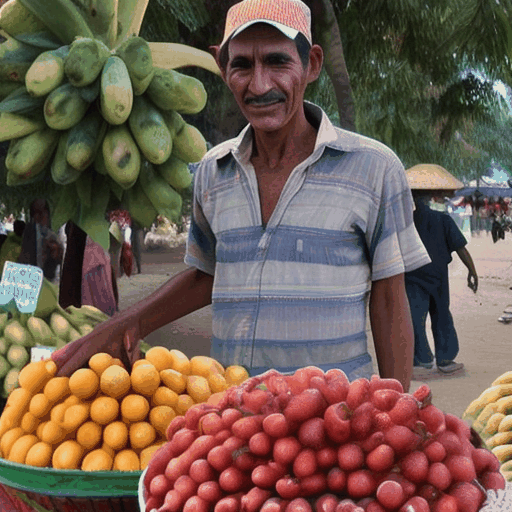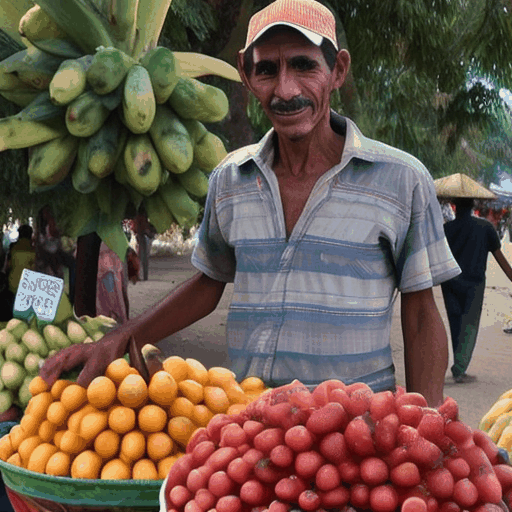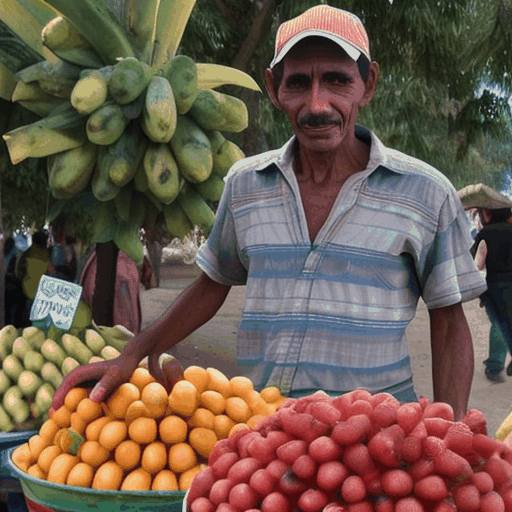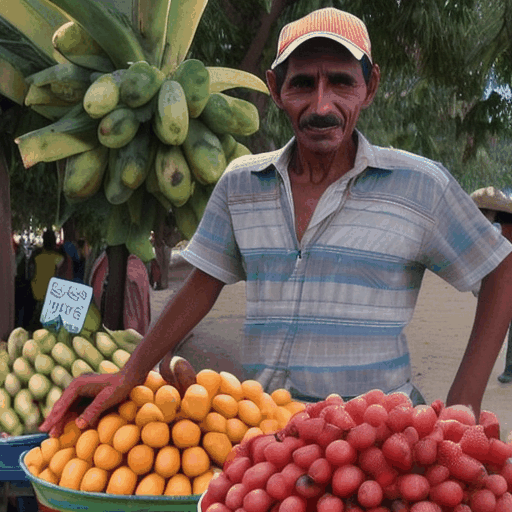
6. LaVie + VideoGuide












As demonstrated in the samples above, our VideoGuide is the only method to reliably improve temporal quality of inadequate samples without any unwanted trade-offs. This allows for newfound synergistic effects among models: functions such as personalization can be freely utilized while borrowing the temporal consistency of external models.
7. Prior Distillation

Degraded performance due to a substandard data prior is an issue only solvable through extra training. However VideoGuide provides a workaround to this matter by enabling the utilization of a superior data prior. Generated samples are guided towards a result of better text coherence while maintaining the style of the original data domain. For each prompt, the same random seed is shared for both methods.